
Berechne, wie viel Chaos in dir steckt
Hast du dich je gefragt, wie viel Chaos in dir steckt? Du musst dazu keinen Persönlichkeitstest machen oder die Sterne befragen. Stattdessen können wir mit ein wenig Mathematik herausfinden, was dein Name in die Welt trägt.

Gut, gut, ich muss zugeben, dass das ein ziemlich übertriebener Aufhänger war. Wir thematisieren heute die Entropie in der Informationswissenschaft und wie wir von einem Datenstrom, wie beispielsweise einem Namen, die Entropie berechnen können. Dazu schlage ich allerdings zunächst einen ziemlich großen Bogen:
Die Entropie in der Physik
Rudolph Clausius definierte den Begriff Entropie und sagte, die Entropie würde immer zu einem Maximum streben. Aber was ist die Entropie? Man hört ja die verschiedensten Erklärungen dazu. Ist es Wärme, ist es Chaos? Ehrlich gesagt, ist es nichts davon. Stattdessen ist Entropie der wahrscheinlichste Zustand. Es ist die Gleichmäßigkeit, mit der Energie verteilt ist.
Energie ist am nutzbarsten, wenn sie konzentriert ist. Deshalb nutzen wir Zucker und Fett für unseren Stoffwechsel und Öl zum Heizen, denn in diesen Stoffen liegt Energie sehr konzentriert vor, was heißt, ihre Entropie ist niedrig.
Nehmen wir als Beispiel einen großen, heißen Block Metall. Die Energie ist in ihm sehr konzentriert, darum können wir sie nutzen, um beispielsweise Wasser zu verdampfen und eine Dampfturbine zu betreiben. Lassen wir den großen, heißen Block Metall aber einfach liegen, strebt die Entropie zum Maximum, was bedeutet, dass sich die Wärme gleichmäßig im ganzen Raum verteilt. Dann ist die Energie nicht weg, nach dem Energieerhaltungsgesetz kann sie nicht verschwinden. Da sie aber weniger konzentriert vorliegt, ist sie weniger nutzbar für uns, wir können nun beispielsweise keine Dampfturbine mehr betreiben.
Dieser Prozess der Wärmeausbreitung ist ein ähnlicher Prozess wie die Diffusion. Haben wir viele Teilchen auf engem Raum und bieten ihnen Platz zum Ausbreiten, werden sie sich im Laufe der Zeit gleichmäßig im Raum verteilen. Das liegt allerdings genauso wie mit der Wärme nicht daran, dass sich die Teilchen untereinander absprechen könnten, sondern weil es schlichtweg das Wahrscheinlichste ist.
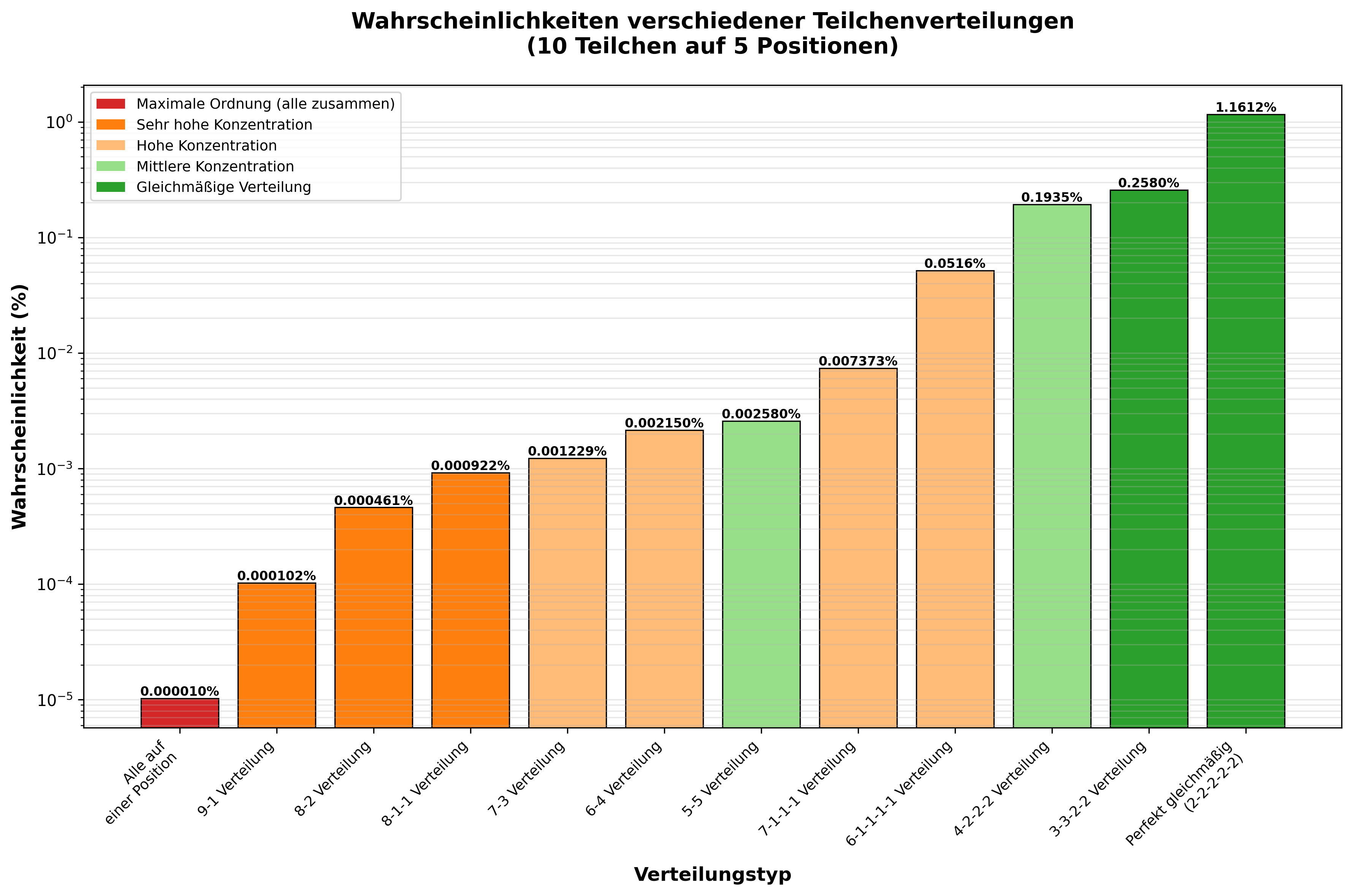
Betrachten wir ein Beispiel mit 10 Teilchen, die ihre Position aus 5 möglichen Positionen wählen (wobei jede Position genügend Platz für alle Teilchen bietet). Wir wollen die Wahrscheinlichkeit berechnen, dass alle 10 Teilchen auf der gleichen Position landen, und die Wahrscheinlichkeit, dass auf jeder Position genau 2 Teilchen landen.
Wahrscheinlichkeit, dass alle 10 Teilchen auf der gleichen Position landen:
Es gibt 5 mögliche Positionen, auf die die Teilchen fallen können. Wenn alle 10 Teilchen auf der gleichen Position landen, gibt es nur 5 mögliche Konfigurationen (alle auf Position 1, alle auf Position 2, usw.). Die Gesamtzahl der möglichen Konfigurationen, in denen 10 Teilchen auf 5 Positionen verteilt werden können, beträgt $5^{10}$ (da jedes Teilchen unabhängig eine der 5 Positionen wählen kann).
Die Wahrscheinlichkeit, dass alle 10 Teilchen auf der gleichen Position landen, ist also:
$$P(\textrm{alle auf einer Position})={5\over 5^{10}}$$ $$={1\over 5^9} ≈ 0.00009537%$$
Wahrscheinlichkeit, dass auf jeder Position genau 2 Teilchen landen:
Um die Wahrscheinlichkeit zu berechnen, dass auf jeder der 5 Positionen genau 2 Teilchen landen, verwenden wir die multinomiale Verteilung. Die Anzahl der Möglichkeiten, 10 Teilchen so zu verteilen, dass auf jeder der 5 Positionen genau 2 Teilchen landen, ist gegeben durch:
$${10!\over 2!\cdot 2!\cdot 2!\cdot 2!\cdot 2!}$$
Die Gesamtzahl der möglichen Konfigurationen bleibt $5^{10}$. Daher ist die Wahrscheinlichkeit, dass auf jeder Position genau 2 Teilchen landen:
$$P(\textrm{2 auf jeder Position})={{10!\over {2!}^5}\over 5^{10}}$$ $$={3628800\over 32\cdot 9765625} ≈ 0.0113%$$
Offensichtlich ist $P(\textrm{2 auf jeder Position})$ mehr als 100-fach höher als $P(\textrm{alle auf einer Position})$. Daher ist nachvollziehbar, warum die Entropie stets zum Maximum strebt.
Thermodynamik
Die thermodynamische Definition der Entropie konzentriert sich darauf, dass die Veränderung innerhalb eines Systems mit der Energie zusammenhängt, die es in dem Prozess verliert. Je mehr Wärme ein System abgibt, umso weniger ist es in der Lage, “Arbeit” zu verrichten.
Wenn $S$ die Entropie, $\delta Q$ der Anstieg ausgetauschter Wärme und $T$ die Temperatur des Systems ist, können wir die Veränderung in der Entropie wie folgt berechnen:
$$dS={\delta Q\over T}$$
Statistische Physik
Aus Sicht der statistischen Physik befinden sich alle Atome und Moleküle in bestimmten Energiezuständen, beispielsweise elektronische Freiheitsgrade, Rotations- und Schwingungsfreiheitsgrade. Die unterschiedlichen Energieniveaus sind nicht kontinuierlich, sondern diskret. Wie die Moleküle auf die möglichen Zustände verteilt sind, wird einzig von der Temperatur bestimmt.
Wenn wir also die Aufteilung der Atome oder Moleküle auf die Energiezustände mit ${n_0, n_1, n_2, …}$ beschreiben, hätten wir bei 0°K (dem absoluten Nullpunkt) folgende Aufteilung: ${N, 0, 0, …}$, wobei $N$ die Anzahl der Teilchen ist. Wenn die Temperatur dann ein kleines bisschen erhöht wird, verteilen sich die Teilchen breiter über die Energiezustände, wobei wir nicht vorhersagen können, welche Teilchen in welche Zustände kommen, sondern nur, mit welcher Wahrscheinlichkeit sich ein Teilchen in welchem Zustand befindet: ${N-2, 2, 0, …}$
Um die Entropie eines solchen Systems zu berechnen, nutzen wir dann die Boltzmann-Entropie. Die Boltzmann-Entropie ist definiert als $$S=k_B ln\left({N!\over n_0!n_1!n_2!…}\right)$$ $$\ =-Nk_b\sum_i p_i ln(p_i)$$
Wobei $k_B$ die Boltzmann-Konstante und $p_i={n_i\over N}$ der Anteil der Moleküle im Zustand $i$ ist.
Ich weiß, dass diese Formel jetzt etwas erschlagend ist, aber für das Verständnis der folgenden Berechnungen ist es sehr wichtig, dass beide Darstellungen dieser Formel verstanden werden. Deshalb möchte ich die beiden Darstellungen kurz erläutern.
Die Boltzmann-Entropie berechnen wir in der ersten Darstellung mit der Konstanten $k_B$ und dem natürlichen Logarithmus eines Quotienten. Dieser Quotient ist das Verhältnis von der Fakultät der Gesamtzahl der Moleküle zu dem Produkt der Fakultäten der Molekülzahlen in jedem Energiezustand. Das ganze kann umformuliert werden, dann haben wir $(-1)$ mal der Gesamtzahl der Moleküle mal der Boltzmann-Konstanten mal einer Summe. Diese Summe summiert über alle Energiezustände das Produkt aus der Wahrscheinlichkeit, dass ein Molekül sich in diesem Zustand befindet, und dem natürlichen Logarithmus dieser Wahrscheinlichkeit.
Eine hohe Entropie bedeutet in der Physik, dass es eine hohe Anzahl möglicher Mikrozustände gibt, die zu dem beobachteten Makrozustand führen. Eine niedrige Entropie hingegen bedeutet, dass es nur wenige Mikrozustände gibt, die zu dem untersuchten Makrozustand führen können. Aus diesem Grund bedeutet eine hohe Entropie in der Physik, dass der Zustand sehr wahrscheinlich ist, beispielsweise wenn alle Teilchen gleichmäßig im Raum verteilt sind (wahrscheinlich) im Gegensatz zu allen Teilchen auf einer einzigen Position (unwahrscheinlich).
Die Entropie in der Informationswissenschaft
Wenn wir dieses Konzept auf die Informationswissenschaft übertragen wollen, nutzen wir die Shannon-Entropie. Die Shannon-Entropie ist eng mit dem Informationsgehalt eines Ereignisses verknüpft.
Wenn wir das Ereignis $A$ haben und $p(a)$ die Wahrscheinlichkeit für dieses Ereignis ist, dann berechnen wir zunächst den Informationsgehalt $I(A)$ wie folgt: $$I(A) = -\log_2(p(a))=\log_2\left({1\over p(a)}\right)$$
$I(A)$ gibt an, wie viele Ja/Nein-Fragen man durchschnittlich benötigt, um das Ereignis $a$ zu identifizieren. Je unwahrscheinlicher also ein Ereignis $a$ ist, desto mehr Information liefert es. Die Basis 2 wird hier übrigens beim Logarithmus verwendet, weil wir in Bits als die kleinstmögliche Informationseinheit rechnen. Das liegt nicht etwa daran, dass wir einen Computer zum Rechnen verwendet, sondern weil es schlicht die natürlichste Wahl für binäre Entscheidungen ist, da jede Ja/Nein-Frage genau einem Bit Information entspricht.
Wenn wir nun eine diskrete Zufallsvariable $X$ haben, die der Wahrscheinlichkeitsverteilung $p(x)$ folgt, müssen wir zum Berechnen der Shannon-Entropie $H$ nur den Erwartungswert des Informationsgehaltes ausrechnen. Die Entropie ist in der Informationswissenschaft dann der erwartete Informationsgehalt aller möglichen Ausgänge. Dazu nutzen wir die bekannte Formel zum Berechnen des Erwartungswertes diskreter Zufallsvariablen: $$H(X) = E\left[I(X)\right] = E\left[-\log_2(p(x))\right] = -\sum_i p(x_i) \log_2(p(x_i))$$
Anmerkung: Ich habe zur besseren Lesbarkeit den Faktor $(-1)$ aus der Summe gezogen
Ist $X$ hingegen eine stetige Zufallsvariable mit der Wahrscheinlichkeitsdichtefunktion $p(x)$, dann können wir mit einem Integral auch in diesem Fall die Shannon-Entropie berechnen: $$H(X) = E\left[I(X)\right] = E\left[-\log_2(p(x))\right] = -\int p(x) \log_2\left(p(x)\right) dx$$
Hierbei besteht aber ein wesentlicher Unterschied zur physikalischen Entropie. Während eine hohe Entropie in der Physik nämlich bedeutet, dass ein Zustand sehr Wahrscheinlichkeit ist, bedeutet eine hohe Entropie in der Informationswissenschaft, dass ein Ereignis vor seinem Eintreten sehr ungewiss ist. Wenn wir also ein Ereignis zu 90% vorhersagen können (weil z.B. in 9 von 10 Fällen eine 1 kommt), ist die Entropie deutlich geringer, als wenn wir das Ereignis nur zu 50% vorhersagen können. Die maximale Entropie in der Informationswissenschaft erreichen wir, wenn alle Wahrscheinlichkeiten gleich verteilt sind und wir daher keine gute Vorhersage treffen können.
Anwendungsfälle
Sehen wir uns beispielsweise einen Münzwurf $M$ mit $p({Kopf}) = p({Zahl}) = 0.5$ an. Der Informationsgehalt eines einzelnen Ereignisses, beispielsweise Kopf, beträgt: $$I({Kopf}) = -\log_2(0.5) = 1 {Bit}$$
Konkret bedeutet das, dass wir beim Wurf von Kopf ein Bit an Information erzeugen, nämlich dass Kopf zu sehen war.
Die Entropie der Zufallsvariablen $M$ ist der erwartete Informationsgehalt aller beiden Ausgänge, also: $$H(M) = -\sum_i p(m_i) \log_2(p(m_i))$$ $$= -\left(0.5 \log_2(0.5) + 0.5 \log_2(0.5)\right) = -(-0.5 - 0.5) = 1 {Bit}$$
Eine Entropie von einem Bit sagt uns, dass wir bei unserem fairen Münzwurf im Schnitt 1 Bit an Information pro Wurf erzeugen.
Bei einem fairen, sechsseitigen Würfel (Ereignis $W$, $p(w) = 1/6$) haben wir eine Entropie von: $$H(W) = -\sum_i p(w_i) \log_2(p(w_i)) = -6 \cdot \left(\frac{1}{6} \log_2\left(\frac{1}{6}\right)\right) = 2.58 {Bits}$$
Hier sehen wir sehr gut, dass sich die Anzahl aller Ereignisse aus der Summe ($6$) mit der jeweiligen Wahrscheinlichkeit ($1/6$) bei gleichverteilten Zufallsvariablen aufheben und aus diesem Grund bei gleichverteilten Zufallsvariablen die Entropie immer gleich dem Informationsgehalt der einzelnen Ereignisse ist.
Aus diesem Grund wollen wir noch eine ungleich verteilte Zufallsvariable betrachten, beispielsweise die Zeichenfolge $Z = 01001000$.
Diese Zeichenfolge ist acht Zeichen lang, davon zwei mal die $1$ und sechs mal die $0$. Darum ist $p(z = 1) = \frac{2}{8} = 25 \%$ und $p(z = 0) = \frac{6}{8} = 75 \%$.
Die Entropie können wir also wie folgt berechnen:
$$H(Z) = -\sum_i p(z_i) \log_2(p(z_i)) $$ $$= -\left(\frac{2}{8} \cdot \log_2\left(\frac{2}{8}\right) + \frac{6}{8} \cdot \log_2\left(\frac{6}{8}\right)\right) = 0.81 Bits$$
Hierbei handelt es sich natürlich um die durchschnittliche Anzahl an Bits, die jedes Ereignis (also jede 0 oder 1) erzeugt. Da die gesamte Zeichenfolge aus 8 Zeichen besteht, hat die Zeichenfolge eine Entropie von $8 \cdot 0.81 = 6.48 Bits$ (bzw. $6.49 Bits$, wenn man ohne Rundungsfehler rechnet).
Aus der Entropie lässt sich die theoretisch maximal mögliche verlustfreie Kompressionsrate ableiten: Im Mittel kann eine verlustfreie Kodierung nicht weniger Bits pro Symbol verwenden als die Entropie der Quelle. In der Realität können sich Komprimierungsalgorithmen dieser Grenze nur annähern, aber sie bietet einen guten Anhaltspunkt dafür, wie effizient die Komprimierung ist.
Falls Sie nun das Bedürfnis verspüren, die Entropie weiterer Zeichenketten auszurechnen, habe ich Ihnen hier einen Entropie-Rechner programmiert. Probieren sie gerne die von uns soeben manuell berechnete Zeichenkette “$01001000$” oder auch andere interessante Zeichenketten, wie “$aaaa$”, “$1234$” oder auch Ihren Namen.
Ist das nicht fabelhaft? Wir hatten ursprünglich eine rein physikalische Formel, die die Anzahl der Teilchen in gewissen Energiezuständen betrachtet, und diese Formel konnten wir so weit abstrahieren, dass wir nun die Entropie von Würfeln, Zeichenketten usw. berechnen können.
BONUS: Schwarze Löcher
Nach dem Schreiben dieses Artikels habe ich von Veritasium das Video “The Most Misunderstood Concept in Physics” gesehen. Ich kann dieses Video zum Verständnis der physikalischen Entropie sehr empfehlen. Sie erklären zudem, dass die Entropie schwarzer Löcher nicht proportional zu deren Volumen ist, sonder zur Oberfläche des Ereignishorizonts. Das ganze basiert auf Stephen Hawking’s Arbeit über Hawking-Strahlung.
Das bildet eine Art natürliche Obergrenze für die Entropie eines bestimmten Raumes. Die Entropie eines Raums kann nicht größer werden als die eines Schwarzen Lochs der gleichen Größe. Damit ist auch eine grundlegende Grenze für die Informationsspeicherung geschaffen, denn wie oben erwähnt, ist die Entropie der erwartete Informationsgehalt.
